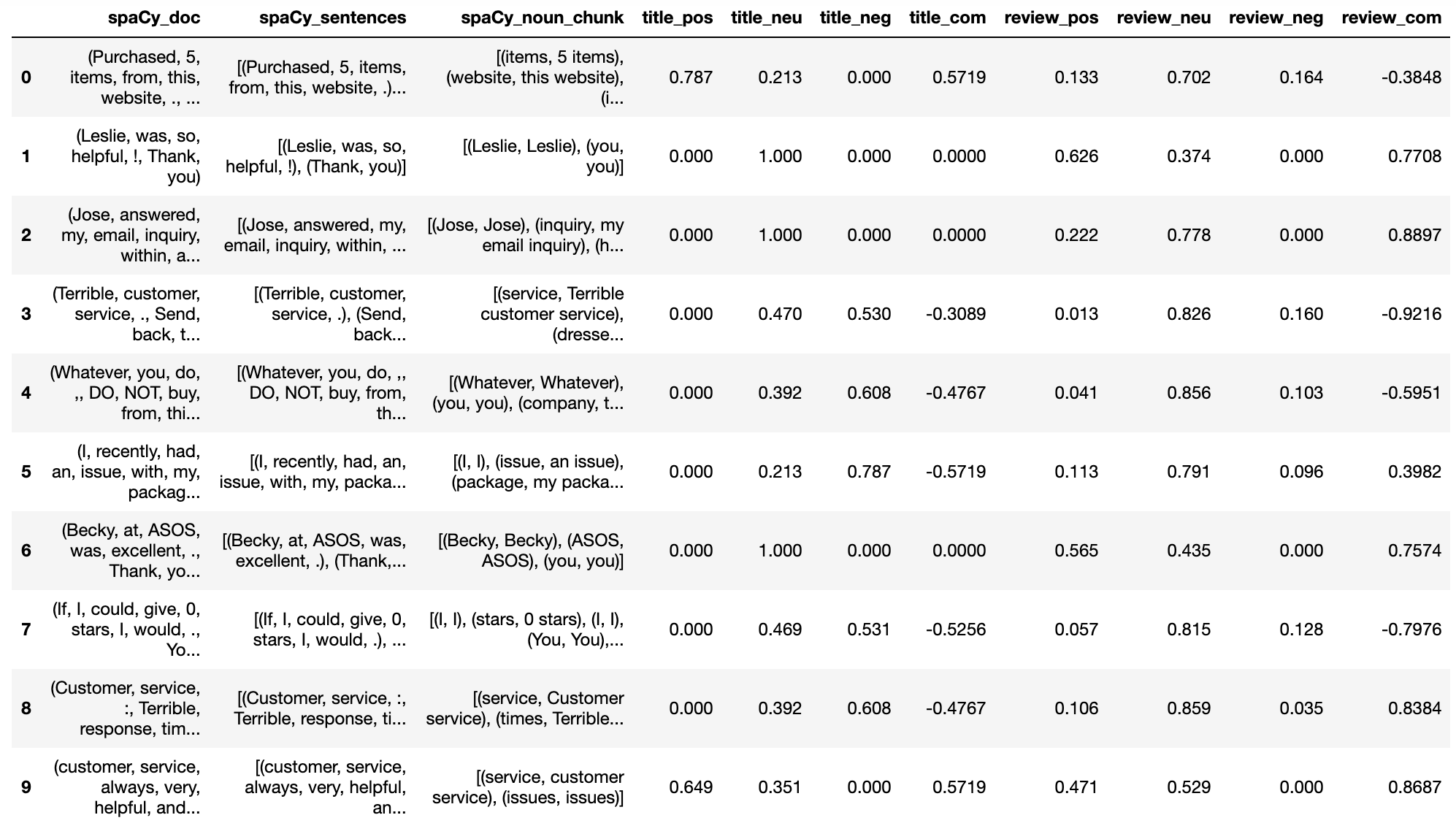
Inspect the Site
We will assess the site and suggest a plan of how to effectively extract data from the site
Examine Existing Features
We will review the existing features in our dataset and assess how we will use them
Create New Features
We will create new features that will broaden the scope of our analysis
Inspect The Site
The first thing we want to do is inspect the site and assess what scraping strategy is appropriate for us to use.
Observation 1 - TrustPilot is reasonably static
There aren’t many interactive elements on the TrustPilot website i.e. scrolling to load more reviews or elements that we need to click in order to load more content to scrape. Dynamic sites like these - whilst maybe improving the UX can be a right pain in the ass to scrape as it means we have to do some form of browser based scraping using something like Selenium. This means scraping can be slow and we don’t want that!
As TrustPilot is reasonably static we can implement a combination of requests and html parsing to make scraping more efficient.
Nice.
Observation 2 - Reviews are paginated

If a review carries over to more than one page, then the next page increases by one. You can do this in the browser by clicking the pagination button but each url has a page identifier which make life a lot easier if we want to scrape content at scale.


All we need to do is generate the right amount of URLS to scrape and it’s as simple as that.
Observation 3 - Be careful of overloading requests to the TrustPilot servers
Most websites will limit the amount of requests made to it. After some tinkering and multiple 403 Errors, I’ve found that a maximum of 100 requests every 2 minutes seems to be ok. If we increase the requests or decrease the wait time I was experiencing 403 after 403. To that end I have built in a few safeguards in the code to prevent this.
Plan
OK great. So broadly speaking this is what we will do:
- Find out how many pages of reviews we need to scrape and generate the URL’s we need
- Batch process the scraping across all review URL’s using some multi-threaded function that implements a combination of requests and html parsing (within the parameters that prevent 403 Errors!)
- Save the data to a structured Pandas DataFrame with the option of sending to a Google BigQuery table
Nice and simple. Let’s do this!
The Code

I have written a custom TrustPilot class that does what we need to do. I’ve built it as a class as it makes sense to be able to repeat this on whatever TrustPilot review we want to get data for. It’s important to make sure our code can be generalised and is future proof.
Code smarter, not harder!
You can get the class here and its accompanying readme for a full breakdown of functionality. I’ve also included a GitHub gist below to show the code too.
The Output
The TrustPilot scraper class outlined above has a method that returns a Pandas DataFrame.
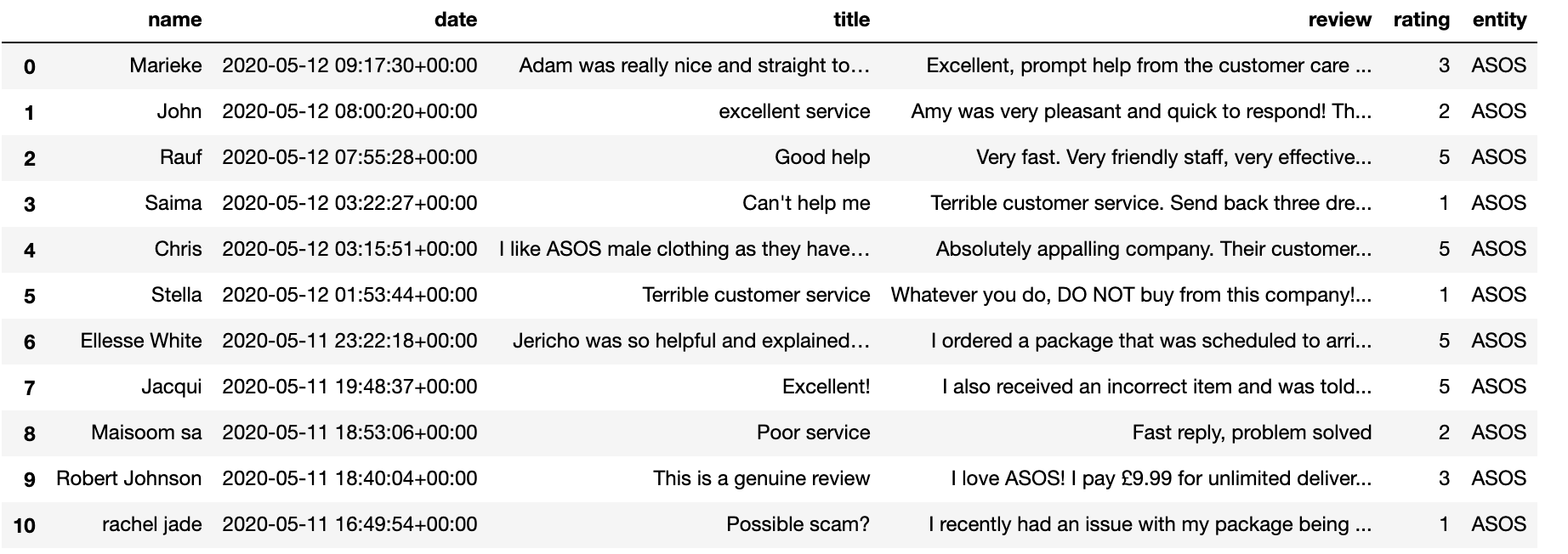
Great. Now we need to examine these features and create some more. It’s always useful to find new features in our data: to open up new analytical opportunities and when we decide to model to give more data to our model and hopefully improve performance.
Examine Existing Features

Let’s have a look at the existing data we now have access to and explore the data types and what use they might be for analysis and model building.
Name
This is the name of the person who made the review as inputted by themselves.
Implication
We can use gender identification models to reasonably infer the gender of the person making the review. This might be a useful demographic feature to build into analysis and modelling.
Date
This is the date of the review.
Implication
This will be something we want to look at if we want to explore any time series analysis. Extracting day and possibly month might also be useful features for modelling.
Title & Review
This is the title and review text
Implication
The title and review body are the main features we will want to analyse. They will also be what we primarily use as features for our modelling. We will have to consider the range of ways in which we represent these - be that through simple count representations (e.g. One Hot Frequencies / Term Frequency Inverse Document Frequencies) or through something a little more sophisticated (e.g. vectorised word embeddings). We will cover this more in the final chapter for this project.
Ratings
Ratings are based a scale between 1-5, a structured form of data. Users have to decide how good or badly they rate the service using this star system. Scores of 1,2 are intuitively more negative, ratings of 3 are possibly ambiguous or a mixture of positive and negative statements. 4,5 are likely to be more positive
Implication
The first thing we will want do is to explore the language being used by satisfied customers and compare this to dissatisfied customers. There are many ways we might want to frame this. To begin with, let’s categorise reviews as either positive (4,5) or negative (1,2). This will also act as our class system for analysis and for when we build our predictive model.
Entity
This is just the brand / product / service we scraped. If all we are doing is looking at ASOS reviews this means there is no variance in this data and therefore we don’t need to include it in any analysis.
Create New Features

The next main thing we need to think about is creating more features in our data. This can help broaden the scope of our analysis and also are likely to improve our model’s performance if we decide to use them in our model.
Create Classes
Let’s add a column that codes a review as 0,1 (positive,negative)..
Call the function…
#call function to get classes
df['class'] = df['rating'].map(getClasses)
Infer Gender
We can then use some off-the shelf gender packages to infer gender.
Call the function…
#instantiate instance of gender_guesser
gd = gd.Detector()
#call function to get first name
df['gender'] = df['name'].map(lambda x: getGender(x,gd))
Day / Month
We can use pandas.to_datetime to explore more features in the date data we have.
Let’s extract:
- Day of week
- Day of year
- Week of year
- Month-Year (e.g. Jan-2020,Feb-2020..)
- Month
- Quarter
- Year
Call the function…
#call function to get date features
df = getDate(df,'date')
Length of Review
#get length of review
df['review_length'] = df['review'].map(lambda x: len(x))
Let’s have a look at what we have now…
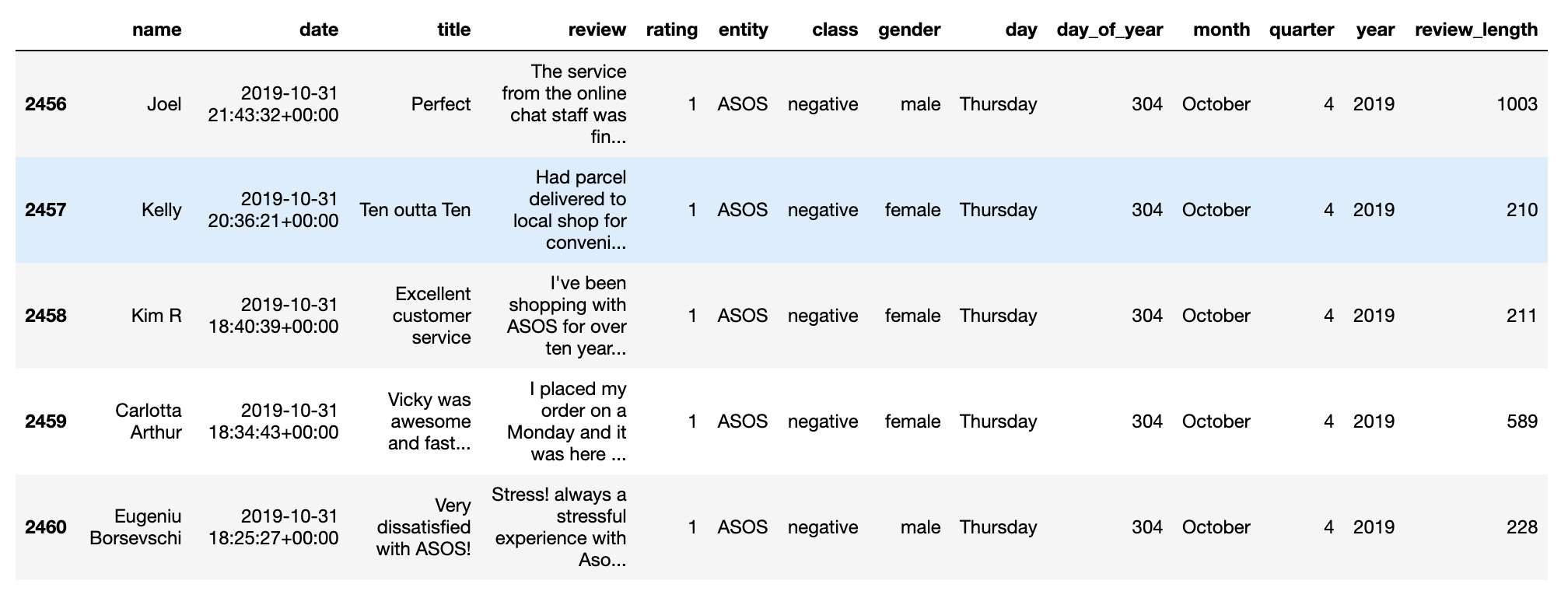
Great, let’s now add some linguistic features.
Get Noun Chunks
Noun chunking is a useful analytical process we can apply in order to understand what people are a talking about.
We will discuss this in more detail further down below. For now let’s just build the code that generates a spaCy doc and the relevant spaCy sentences and spaCy noun chunks for each review.
Call the function…
#call getspaCy function on review column
df = getspaCy(df,'review')
Get Sentiment (using vaderSentiment)
We can use a quick and dirty sentiment analysis on both the title and review text. It will be interesting to see if this naturally correlates with user ratings! Furthermore, because the vaderSentiment pos,neu,neg output sums to 1, we can analyse the distribution of sentiment by post using ternary plots.
Call the function…
#call getSentiment function on title and review columns
df = getSentiment(df,'title','review')
Ok great - let’s have a look at those new features we have built.