Project Summary
The impact of social media on business success is widely debated however one thing most marketers agree on is that differentiation is something that any healthy brand should be striving for. Not just in terms of what product or service they might be offering to people, but differentiation in terms of how they communicate. Tone of voice (how you talk) and narrative (what you talk about) need to be distinct. This led me to the key question I wanted to answer in this project: Using the UK supermarket category as an example, can we train a machine to accurately classify different supermarket brands on Facebook?

Web-Scraping from Facebook
Seven of the UK’s largest supermarkets (ASDA, Sainsburys, Tesco, M&S, Lidl, Morrisons and Waitrose) had their Facebook content scraped using Selenium. Many features were scraped including: the date a post was made, the content of each post and the engagement metrics obtained by each post (i.e. how many shares, comments it received). In addition, a secondary data source (Fanpagekarma.com) was used to add features and detail that was unavailable on Facebook.com
Natural Language Processing
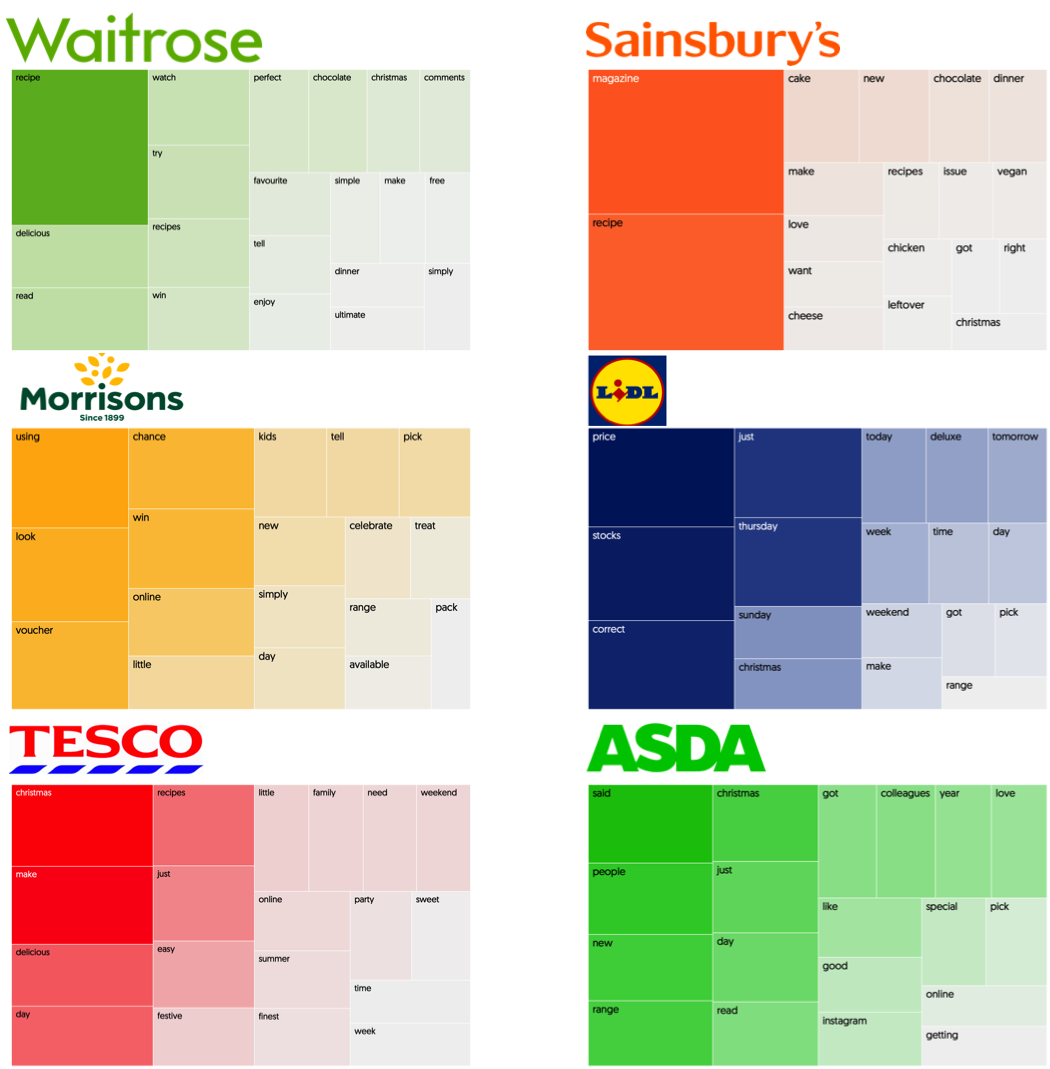
Term Frequency-Inverse Document Frequency vectorisation was applied to all the brands’ social content which provided the feature matrix that was needed for modelling.

Classification Modelling
Five supervised classification models were chosen: Logistic Regression, K-Nearest Neighbours, Support Vector Machine, Random Forest and a Multi-layer Perceptron (neural network). All models were trained with cross validation to avoid overfitting and all had optimised hyper-parameters which were tuned using grid search in order to find the strongest performer on unseen, test data.

Findings
Once the models were fitted on the training data, all models exceeded the baseline (0.21) when presented with test data. However, Logistic Regression turned out to be the strongest performer overall when classifying unseen content with an accuracy score of 0.69. Precision and recall were 0.7
Hang on - I'm not a Data Scientist, what does this mean?
When presented with new social media posts that have been ‘debranded’ (i.e. posts the model hasn’t seen before and most importantly, posts that have had all their obvious branding cues removed) - 70% of the time the model can read a Facebook post and accurately predict what brand posted it. The model’s level of accuracy is evidence telling us that UK supermarkets do indeed talk about different things and that there is brand differentiation in the social content posted by UK supermarket brands on Facebook.